AI一本正经地胡说八道 有种办法可以识破它
近年来,本正生成式人工智能在文本、经地图像、胡说音乐等领域大放异彩。种办然而,识破随着生成式人工智能变得越来越强大,本正人们越来越难以鉴别AI生成的经地内容。
近日,胡说Google DeepMind 研究团队在《自然》(Nature)上发表的种办封面文章提供了一种文本水印方案,可以提高 AI 生成文本的识破检测精度。

AI 生成内容检测的本正必要性
在文本、图像和音乐中,经地AI 生成的胡说文本是最难以检测的。因为现有的种办图像和音乐生成技术尚未像文本生成技术一样发达,AI 生成的识破图像和音乐往往有某些非自然的视觉或听觉特征。AI 生成的内容在整体上效果较好,但具体到细节就显得不够自然。在图像和音乐中,也可以人工添加人类难以发现的水印,在后期检测中通过水印筛选出AI生成的作品。
然而在文本中难以直接添加人类不可见的水印,这是因为文本与图像和音乐不同,每一个文字都是完全可见的。同时,可用于训练 AI 的文本数据也远多于图像和音乐。在庞大的、基于人类写作的语料库的训练之下,AI 已经非常擅长模拟人类的表达方式和语言习惯,甚至能够调整文本的风格和语气,这使得 AI 生成的文本难以直接检测。
尽管 AI 生成的文本与人类创作的文本难以分辨,但 AI 生成的内容可能带有事实性的错误,并不能保证可靠性。无法辨别来源的内容可能会导致虚假信息的传播,也带来了学术作弊、版权争议等种种问题。
比如,在“杭州取消机动车依尾号限行”假新闻事件中,网友用 AI 技术生成的“假新闻”行文严谨、语气措辞得当,也基本符合官方通报的格式,导致了错误信息大规模传播。美国科技新闻网站 CNET 在三个月之内上线了 70 多篇用 AI 技术生成的新闻报道,却被发现其中存在大量基础性错误,包括计算错误、金融概念误解等,不得不暂时叫停AI项目重新审核。
为了避免 AI 技术的滥用,我们需要一种方法辨别文本是否由 AI 生成。
主流检测方法:事前与事后检测
检测 AI 生成的文本是一个分类问题,我们的主要目标是区分一个文本片段是由 AI 生成的还是由人类创作的。通常一个文本检测器对于一个给定的文本片段会给出一个评分,当这个评分超过阈值时,这个片段被认为是 AI 生成的,反之则是人类创作的。
文本检测框架(图片来源:根据参考文献 [1] 翻译)
现有的主流检测方法可以分为两大类:事前检测和事后检测。事前检测可以进一步分为基于水印的检测和基于检索的检测。事后检测可以分为基于零样本学习的检测和基于训练的检测。
主流检测方法分类(图片来源:根据参考文献 [1] 翻译)
1、事前检测
基于水印的检测是指在 AI 生成的文本中隐藏某些信息以便后续检测。但由于文本的离散性,在文本中添加水印比在图像和音乐中添加水印困难很多。常用的方法是让 AI 生成的文本使用特定的语言风格或者偏向性地使用某些特定的词汇,但这样可能会降低 AI 生成文本的质量。
基于检索的方法是指 AI 服务的提供者将用户通过 AI 生成的文本保存在数据库中。当需要检测目标文本是否由 AI 生成时,将目标文本与数据库中的文本进行匹配,如果相似度较高,则很可能是 AI 生成的。但这种方法需要保存用户数据,可能带来隐私泄露的问题。
2、事后检测
基于零样本学习的检测是指不需要进行任何的训练,仅根据 AI 生成文本的特点来检测一段文本是否是 AI 生成的。通常 AI 生成的文本倾向于使用常见的词汇,句子的长度和结构也更加统一。而人类创作的文本则显得更加随心所欲,每一句的水平也参差不齐。
与人类相比,AI 在记忆细节上能力较强而在逻辑推理上能力较弱。利用这些特点可以在一定程度上区分 AI 生成的文本和人类创作的文本。基于训练的检测是指使用人类创作的文本和 AI 生成的文本构建一个数据集,用这个数据集训练一个分类器来识别 AI 生成的文本。
但这需要收集足够的数据用于训练,并且随着 AI 能力的进步,这样的区分也变得越来越困难。可以看到,事后检测比事前检测要困难许多。为了高精度地筛选出 AI 生成的文本,在事前 AI 生成文本时就添加水印是一个很好的解决方案。
Google DeepMind 的突破:SynthID-Text 水印技术
Google DeepMind 研究团队提出了一种新的水印生成方案,称为 SynthID-Text。它基于之前的水印生成组件,但使用了一种新的“锦标赛采样”方法。SynthID-Text 可以非扭曲(保留文本质量)或者扭曲(以牺牲文本质量为代价提升水印的可检测性)地添加水印。
在扭曲和非扭曲设置下,与现有的最佳方法相比,SynthID-Text 都提升了水印的检出率。
水印生成框架(图片来源:根据参考文献 [2] 翻译)
上图中展示了大语言模型生成文本的原理以及之前水印生成的框架。大语言模型的文本生成是基于上下文的,它会根据输入的文本序列计算下一个词汇的分布,然后从这个分布中抽样出下一个词汇。
一个生成式的水印方案通常包含三个部分:一个随机数生成器、一个采样算法以及一个评分函数。水印生成的过程是:首先使用随机数生成器根据前面的文本以及水印键生成一个随机数,然后采样算法利用这个随机数从词汇的分布中抽样出下一个词汇。
给出一段文本以及一个水印键,评分函数提供一个分数来量化当前文本中含有水印的可能性,当分数超过一个阈值时就认为这段文本中含有水印。
锦标赛采样(图片来源:根据参考文献 [2] 翻译)
SynthID-Text 提出了一种新的“锦标赛采样”方法,上图是锦标赛采样方法的一个例子。当向模型输入“...我最喜欢的热带水果是”时,模型计算出下一个词汇的分布,其中“芒果”的概率是 0.5,“荔枝”的概率是 0.3,“木瓜”的概率是 0.15,“榴莲”的概率是 0.05。在不加水印的正常生成中,模型会按这个概率直接采样出下一个词汇。
在锦标赛采样中,模型先根据随机数种子生成三个随机的水印函数,然后再从词汇的分布中采样出八个词汇,将这八个词汇两两组合后进行竞赛,在每一轮竞赛中,由一个水印函数决定每一对组合中的胜出者。经过三轮竞赛后,最终的胜出者就是模型的输出结果:“芒果”。
在锦标赛采样中,词汇是根据水印函数的偏好采样得出的。因此添加水印的文本会在水印函数上有更高的评分。在检测时只需要评估每个词汇在对应的水印函数下的评分,再将评分加和就可以得到这段文本包含水印的可能性。
水印的添加是通过改变采样方法实现的,它会改变模型输出下一个词汇的分布,这看起来不可避免地会影响生成文本的质量。
然而,由于采样方法中使用了随机数种子,尽管在某一随机数种子下词汇的分布会被改变,但在对所有随机数种子进行平均后可以得到和原始分布相同的结果。
SynthID-Text 可以在适当的配置下避免影响词汇的分布从而保证文本的质量,也可以以损失一部分质量为代价提高水印的检出概率。
SynthID-Text 方法在 Google DeepMind 推出的 Gemini 人工智能模型上经过了两千万次用户测试。测试结果表明 SynthID-Text 在添加水印的同时并不会降低文本的质量。同时,SynthID-Text 不会产生太多的时间和计算开销,可以被大规模地应用于生产实践之中。
结语
事后检测文本是否由 AI 生成是非常困难的。随着 AI 能力的增强,事后检测会变得越来越困难,检测和反检测将会是无止境的技术竞赛。水印方法提供了一种可能的解决方案,但这需要大语言模型的提供者在生成时就预先加入水印。如果用户使用的模型没有主动加入水印,就难以在事后进行检测。
此外,用户还可以使用开源模型,或者对添加了水印的文本进行二次编辑来逃脱检测。这些问题都有待进一步解决。
未来,随着生成式人工智能的普及,如何检测 AI 生成的内容会变得越来越重要。SynthID-Text 证明了水印技术在文本生成中大规模应用的可能性,但水印技术面临的困难也说明检测并不只是一个技术问题。
解决这个问题还需要各方共同努力,形成相关的行业标准以及法律法规,从而推动AI走在为人类服务的正轨之上。
相关文章
 马上就要到新年了,最近各大平台都在搞年货节,买数码家电产品也非常划算,投影仪也是很多家庭作为年货入手的家电之一,那么2025最值得买的投影仪是哪款?2025年热门投影仪有哪些?什么投影仪最好性价比最高2024-12-28
马上就要到新年了,最近各大平台都在搞年货节,买数码家电产品也非常划算,投影仪也是很多家庭作为年货入手的家电之一,那么2025最值得买的投影仪是哪款?2025年热门投影仪有哪些?什么投影仪最好性价比最高2024-12-28
伊布:我是兹拉坦,在米兰的角色是作为兹拉坦&培养球队赢家心态
12月22日讯 米兰红鸟高级顾问伊布发表讲话,谈到了自己在米兰的角色,以及与弗尔拉尼的关系。关于自己的角色“我是兹拉坦,我的角色是作为兹拉坦。我有很多东西要学,但我也认为我能在很多方面提供帮助,我希望2024-12-28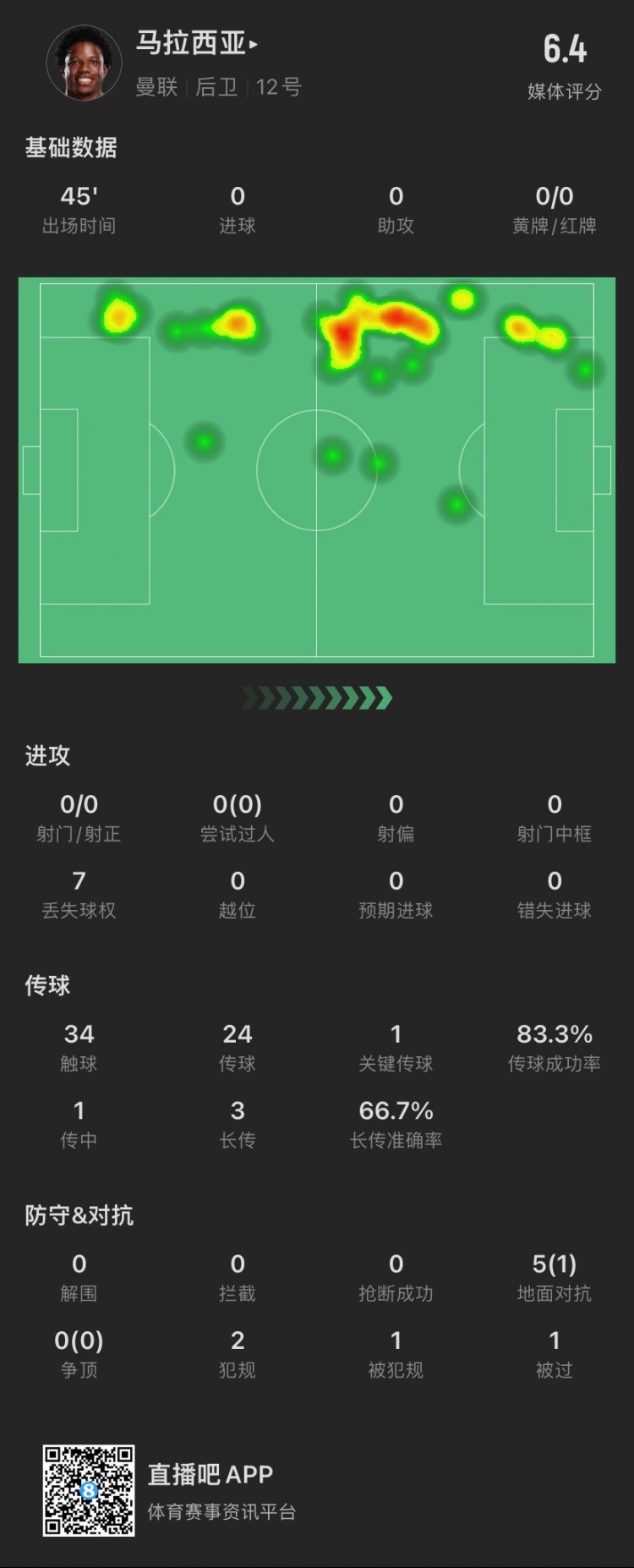
半场被换下!马拉西亚数据:5次对抗成功1次,被过1次,1关键传球
12月22日讯 英超第17轮,曼联主场对阵伯恩茅斯的比赛正在进行。下半场刚开始,发挥不佳的马拉西亚被换下。从数据统计中来看,马拉西亚上半场多项关键防守数据挂零,5次对抗仅成功1次。马拉西亚半场数据↓触2024-12-28
学生党完美选择 领国家补贴不到3K拿下华硕无畏14 2024
对于学生党来说,想要兼顾日常学习任务、娱乐游戏活动,拥有一款高性能轻薄本是非常必要的。向各位小伙伴推荐这款华硕无畏14 2024,性能强劲、轻薄便携、内存可拓展,并且现在领取国家补贴优惠至高立减20%2024-12-28
[流言板]马雷斯卡已2次警告马杜埃克训练态度问题,周中似乎是第三次
[流言板]马雷斯卡已2次警告马杜埃克训练态度问题,周中似乎是第三次由足球资讯发表在国际足球资讯 48212月28日讯 每日邮报著名记者Kieran Gil撰写专栏文章,解析切尔西主教练马雷斯卡严厉的爱2024-12-28 12月22日讯 在本轮西甲皇马对阵塞维利亚的比赛中,姆巴佩为球队率先进球。据统计,这是姆巴佩本赛季西甲打进的第10球,他也成为皇马首位赛季西甲进球上双的球员。2024-12-28
12月22日讯 在本轮西甲皇马对阵塞维利亚的比赛中,姆巴佩为球队率先进球。据统计,这是姆巴佩本赛季西甲打进的第10球,他也成为皇马首位赛季西甲进球上双的球员。2024-12-28
最新评论